









BAB I
PENDAHULUAN
A. Latar Belakang
Statistics is difficult to learn. Begitulah salah contoh dalam buku Bahasa Inggris pegangan mahasiswa. Pernyataan bahwa statistik sulit untuk dipelajari tidaklah berlebihan. “Jika orang mendengar kata statistik, maka asosiasi mereka adalah tentang sesuatu yang ruwet, memusingkan, penuh dengan rumus-rumus yang rumit, membosankan, dan sebagainya.” Mahasiswa yang menulis skripsi dengan pendekatan kwantitatif ternyata menemukan banyak kesulitan untuk menentukan analisis statistik yang tepat dan mengaplikasikan analisis yang telah dipilih.
Dengan semakin meluasnya ketersediaan komputer pada lembaga pendidikan akhir-akhir ini, metode pengajaran Statistik di beberapa perguruan tinggi telah mengalami perubahan yang dramatis. Kusnandar selanjutnya mengatakan bahwa ketersediaan perangkat keras dan lunak komputer telah memberikan banyak kemudahan kepada peneliti dalam menganalisis hasil penelitian. Bila dahulu ada anggapan bahwa penelitian yang meneliti tiga variabel atau lebih hanya dapat dilakukan oleh peneliti setingkat mahasiswa S2 atau bahkan S3, dikarenakan sulitnya analisis multivariat, sekarang itu bisa dilakukan oleh mahasiswa S1 atau oleh peneliti pemula. Singgih Santoso menganggap bahwa perkembangan Software Statistik yang pesat membuat penggunaan metode statistik Multivariat yang sangat komplek menjadi mudah dan praktis. Kalau terhadap statistik Multivariat saja menjadi mudah dan praktis, apalagi bagi statistik univariat dan bivariat.
Kejadian ini, sejauh pengamatan kami belum banyak terjadi di berbagai perguruan tinggi Islam di wilayah Kediri dan sekitarnya. Belum dimanfaatkannya teknologi terbaru untuk analisis statistik ini boleh jadi karena sivitas akademika belum tahu dan masih meragukan tentang berbagai efektivitas, kemudahan, dan validitas dari teknologi itu.
Berangkat dari latar belakang masalah di atas, maka penulis melalui makalah ini berusaha memberikan kesan mudah terhadap statistik dengan memberikan contoh dan aplikasinya dengan SPSS dan Microsoft Excel.
B. Manfaat Statistik dalam Penelitian Kwantitatif
Setidaknya ada 4 (empat) manfaat Statistik dalam penelitian kwantitatif:
1. Untuk menghitung besarnya anggota sampel yang diambil dari populasi, sehingga sampel dapat lebih representatif dan dapat dipertanggungjawabkan.
2. Untuk menguji validitas dan reliabilitas instrumen.
3. Teknik-teknik untuk mendeskripsikan data sehingga data lebih komunikatif; dan
4. Alat untuk analisis data.
C. Macam-macam Statistik
Statistik dapat dibedakan menjadi dua, deskriptif dan inferensial. Statistik Deskriptif adalah statistik yang digunakan untuk menggambarkan data atau menganalisis suatu hasil penelitian tetapi tidak digunakan untuk generalisasi. Sementara statistik inferensial adalah statistik yang digunakan untuk menganalisis data sampel dan hasilnya akan digeneralisasikan.
Statistik inferensial dapat dibedakan menjadi dua, parametris dan non-parametris. Statistik parametris terutama digunakan untuk menganalisis data interval atau rasio yang diambil dari populasi yang berdistribusi normal. Sementara non-parametris terutama digunakan untuk menganalisis data nominal atau ordinal. Atau datanya interval atau rasio tetapi tidak berdistribusi normal. Macam-macam statistik itu dapat digambarkan seperti di bawah ini:
D. Jenis Data
Data hasil penelitian dapat dikelompokkan menjadi dua: kualitatif dan kuantitatif. Data kualitatif adalah data yang berbentuk kalimat, kata, atau gambar. Sedangkan data kuantitatif adalah data yang berbentuk angka, atau kualitatif yang diangkakan.
Data kuantitatif dapat juga dikelompokkan menjadi dua: diskrit dan kontinum. Data diskrit adalah data yang diperoleh dari menghitung, bukan mengukur. Data ini sering disebut dengan data nominal. Sementara data kontinum dikelompokkan menjadi tiga: ordinal, interval, dan rasio. Data ordinal adalah data yang berjenjang dan berbentuk peringkat. Data ordinal ini dapat dibentuk dari data interval atau rasio. Data interval adalah data yang jaraknya sama tetapi tidak mempunyai nol absolut. Sementara data rasio adalah data yang jaraknya sama dan mempunyai nol absolut.
Bermacam data seperti di atas dapat digambarkan seperti di bawah ini:
Contoh data dalam skala pengukuran nominal dan ordinal:
No Skala Penguk. Data Kualitatif Kategori
01 Nominal Suku 1. Sunda 2. Jawa
3.Madura 4. Lainnya
Kepemilikan motor 1. ya 2. tidak
02 Ordinal
Pendidikan 1. PT 2. SMA
3. SMP 4. SD
Jabatan Dosen 1. Guru Besar 2. Lektor Kepala
3. Lektor 4. Asisten Ahli
Nilai Akhir Mata Kuliah 1. A 2. B
3. C 4. D
5. E
Contoh data dalam skala pengukuran interval dan rasio:
Data Kuantitatif Skala Pengukuran
Suhu (Celcius atau Fahrenheit) interval
penanggalan (Masehi atau Hijriah) interval
tinggi (meter) rasio
berat (kilogram) rasio
Umur (tahun atau hari) rasio
E. Pedoman Umum Memilih Teknik Statistik
Terdapat bermacam-macam teknik statistik yang dapat digunakan menguji hipotesis. Teknik statistik mana yang akan digunakan tergantung pada interaksi dua hal: macam data dan bentuk hipotesisnya. Secara singkat dapat dilihat pada tabel di bawah ini:
MACAM DATA BENTUK HIPOTESIS
Deskriptif (Satu Variabel) Komparatif (Dua Sampel) Komparatif (Lebih dari dua sampel) Asosiatif (hubungan)
Related Independen Related Independen
NOMINAL Binomial
X2 One Sample Mc Nemar Fisher Exact Probability
X2 Two Sample X2 for k Sample
Cochran Q X2 for k Sample Contingency Coefficient
ORDINAL Run Test Sign Test
Wilcoxon Matched Pairs Median Test
Mann-Whitney U Test
Kolmogorov-Smirnov
Wald-Woldfowitz Friedman Two-way Anova Median Extention
Kruskal-Wallis One Way Anova Spearman Rank Correlation
Kendall Tau
INTERVAL RASIO t-test T-test of Related T-test of independent
One-way Anova
Two-way Anova
One-way Anova
Two-way Anova Pearson Product Moment
Partial Correlation
Multiple Correlation
Makalah ini tidak akan menjelaskan secara keseluruhan teknik statistik di atas, tetapi hanya menjelaskan teknik yang sering digunakan mahasiswa dalam menguji hipotesis skripsinya.
F. Konsep Pengujian Hipotesis
Pada dasarnya menguji hipotesis itu adalah menaksir parameter populasi berdasarkan data sampel. Terdapat dua cara menaksir, a point estimate dan interval estimate. Yang disebutkan pertama adalah suatu taksiran parameter berdasarkan suatu nilai data sampel sedangkan yang kedua adalah suatu taksiran parameter populasi berdasarkan nilai interval data sampel.
Menaksir parameter populasi menggunakan nilai tunggal mempunyai resiko kesalahan yang lebih tinggi dibandingkan dengan menggunakan interval estimate. Makin besar taksiran maka akan semakin kecil kesalahannya tetapi tingkat ketelitian taksiran semakin rendah. Untuk selanjutnya kesalahan taksiran ini dinyatakan dalam peluang yang berbentuk prosentase. Biasanya dalam penelitian kesalahan taksiran ditetapkan lebih dahulu, yang digunakan adalah 5% dan 1%. Tingkat kesalahan ini selanjutnya dinamakan tingkat signifikansi.
Dalam setiap pengujian hipotesis, kita harus selalu memutuskan apakah menerima ataukan menolak Ho dan selalu ada kemungkinan bahwa kita membuat kesalahan dalam pengambilan keputusan tersebut. Kesalahan tersebut terjadi ketika kita menolak suatu hipotesis yang benar atau menerima hipotesis yanjg salah. Kedua jenis kesalahan ini diberi nama secara khusus dalam pengujian hipotesis:
1. Salah jenis I. Kesalahan ini terjadi ketika kita menolak Ho padahal Ho benar. Peluang terjadinya kesalahan ini dinyatakan dengan dan disebut taraf signifikansi.
2. Salah tipe II. Kesalahan ini terjadi ketika kita menerima Ho padahal Ho salah. Peluang terjadinya kesalahan ini dinyatakan dengan , yang disebut dengan power of statistical test.
Dalam pengujian hipotesis kebanyakan digunakan kesalahan tipe I yaitu berapa prosen kesalahan untuk menolak hipotesis nol (Ho) yang benar. Sebagai ilustrasi dapat dilihat pada gambar di bawah ini:
Daerah Kritis/
Penolakan Ho
Titik
Kritis Daerah
Penerimaan Ho Titik
Kritis
BAB II
ANALISIS KORELASI
A. Pendahuluan
Dalam ilmu statistik istilah korelasi berarti hubungan antardua variabel atau lebih. Hubungan antardua variabel disebut bivariate correlation, sementara hubungan antarlebih dua variabel disebut multivariate correlation.
Hubungan antardua variabel misalnya korelasi antara intensitas mengikuti diskusi dosen (variabel x) dengan produktifitas kerja (variabel y). Hubungan antarlebih dari dua variabel misalnya korelasi antara kwalitas layanan (variabel x1), keadilan bagi hasil (variabel x2), dengan banyaknya nasabah (variabel y).
B. Arah Korelasi
Hubungan antardua variabel atau lebih itu bila dilihat dari arahnya dapat dibagi menjadi dua, yaitu hubungan yang sifatnya searah dan berlawanan arah. Hubungan searah disebut korelasi positif, sementara yang berlawanan arah disebut korelasi negatif.
Jadi, jika variabel x mengalami kenaikan, maka akan diikuti kenaikan variabel y. Itulah korelasi positif. Contohnya bila layanan terhadap nasabah naik (variabel x) maka naik pula jumlah nasabah bank itu (variabel y). Sementara korelasi negatif adalah apabila variabel x mengalami peningkatan mengakibatkan variabel y mengalami penurunan dan sebaliknya. Contohnya bila curah hujan meningkat (variabel x) maka penjualan es akan mengalami penurunan (variabel y).
C. Angka Korelasi
Besar angka korelasi itu berkisar antara 0 sampai 1, baik posisit maupun negatif. Bila dalam penghitungan diperoleh angka korelasi lebih dari 1 berarti telah terjadi kesalahan penghitungan. Bila angka korelasi itu bertanda negatif menunjukkan korelasi antarvariabel itu negatif. Interpretasi kasar terhadap angka korelasi sebagai berikut:
Interval Koefisien Tingkat Hubungan
0,00 – 0,199 Sangat rendah
0,20 – 0,399 Rendah
0,40 – 0,599 Sedang
0,60 – 0,799 Kuat
0,80 – 1,000 Sangat kuat
D. Macam-macam Teknik Korelasi
Setidaknya ada 9 teknik analisis korelasi sebagai berikut.
NO VARIABEL I VARIABEL II TEKNIK
01 Interval/rasio Interval/rasio Product moment
02 Interval/rasio Interval/rasio Korelasi Parsial
03 Interval/rasio Interval/rasio Korelasi Ganda
04 2 atau lebih nominal 2 atau lebih nominal Koefisien Kontigengensi
05 Ordinal Ordinal Spearman
06 Ordinal Ordinal Kendall’s tau
07 Dikotomi buatan Interval/rasio Biserial
08 Dikotomi asli Interval/rasio Point biserial
09 Dikotomi buatan Dikotomi buatan Tetrachoric
10 Dikotomi asli Dikotomi asli Koefisien Phi
Dari sepuluh teknik analisis ini, penulis hanya akan menjelaskan 5 teknik, yaitu nomor 1, 3, 4, 5, dan 6.
1. Product moment
Teknik korelasi ini digunakan untuk mencari hubungan dan membuktikan hipotesis hubungan dua variabel bila data kedua variabel berbentuk interval atau rasio. Karena product moment termasuk parametrik, maka harus memenuhi uji asumsi salah satunya adalah kedua variabel itu berdistribusi normal.
Dua di antara rumus product moment adalah:
rxy =
Dimana :
rxy = Korelasi antara variabel x dan y
x = (Xi – )
y = (Yi – )
rxy =
Rumus terakhir digunakan bila sekaligus akan menghitung persamaan regresi.
Contoh:
Dilakukan penelitian untuk mengetahui ada tidaknya hubungan antara nilai rata-rata dari Mata Kuliah Statistik Pendidikan, Metode Penelitian, dan Metode Penelitian Kependidikan dengan Nilai Skripsi. Penelitian menggunakan nilai sebelum dikonversi dan mengambil sampel sebanyak 35 mahasiswa.
Karena product moment termasuk parametrik, maka setelah data terkumpul dan skor untuk variabel x dan variabel y diuji normalitasnya. Cara termudah untuk menguji ini adalah dengan program SPSS.
Prosedur untuk menguji distribusi data adalah sebagai berikut:
Setelah data dimasukkan klik Analyze Descriptive Statistics Explore, sebagaimana gambar berikut ini:
Setelah itu akan keluar gambar berikut ini:
Pengisian:
1. Destinasikan kedua variabel itu ke dalam kotak Dependent List, dengan memblok kedua variabel itu dan mengeklik panah yang ada di sebelah kiri kotak itu.
2. Pada bagian Display, kliklah kotak Plots.
3. Kemudian kliklah kotak Plots, maka akan keluar gambar di bawah ini.
Oleh karena hanya akan menguji normalitas, maka
1. Aktifkan kotak Normality Plots with tests.
2. Nonaktifkan pilihan stem and leaf.
3. Pilih None pada bagian Boxplot.
4. Setelah itu klik Ok, maka akan keluar output seperti di bawah ini.
Explore
Untuk menguji normalitas dapat digunakan skor Sig. Yang ada pada hasil penghitungan Kolmogorov-Smirnov. Bila angka Sig. Lebih besar atau sama dengan 0,05, maka berdistribusi normal, tetapi apabila kurang, maka data tidak berdistribusi normal. Karena Sig. Untuk variabel x (0,200), dan variabel y (0,163) itu lebih besar dari 0,05, maka kedua data variabel itu berdistribusi normal.
Hal ini juga dapat dilihat pada grafik Normal Q-Q Plot maupun Detrended Normal Q-Q Plot. Untuk Normal Q-Q Plot itu apabila sebaran data dari variabel itu bergerombol di sekitar garis uji yang mengarah ke kanan atas dan tidak ada yang terletak jauh dari sebaran data, maka data tersebut berdistribusi normal. Sementara untuk Detrended Normal Q-Q Plot, apabila datanya tidak membentuk suatu pola tertentu atau menyebar secara acak, maka data itu berarti berdistribusi normal. Sesuai dengan nilai Sig. di atas, maka hasil uji dengan dua model grafik di bawah ini juga menunjukkan kedua data dari variabel itu berdistribusi normal.
Nilai rata Stat Pend. Met. Pen., dan MPP
Nilai Skripsi
Dikarenakan kedua variabel itu distribusi datanya normal, maka dapat dilakukan analisis dengan product moment. Seandainya distribusi datanya tidak normal, maka harus menggunakan analisis non-parametrik, seperti kendall’s tau atau spearman rank.
Prosedur untuk menguji hipotesis dengan product moment adalah sebagai berikut:
Pada data view product moment di atas, klik Analyze Correlate Bivariate, sebagaimana gambar di bawah ini:
Setelah itu akan keluar gambar seperti di bawah ini:
Pengisian:
1. Destinasikan kedua variabel itu ke dalam kotak Variables,
2. Kalau berkeinginan untuk menampilkan rata-rata dan deviasi standar, kliklah Options, maka akan keluar gambar di bawah ini.
3. Setelah itu kliklah pada kotak yang ada di depan Means and …. Setelah itu klik Continue. Abaikan yang lain dan klik Ok, maka akan menghasilkan Output seperti di bawah ini.
Correlations
Dari output di atas, dapat diketahui bahwa jumlah sampel dari penelitian ini adalah 35. Skor rata-rata variabel x adalah 74,1143 dengan deviasi standar 10,05213. Sementara untuk skor rata-rata variabel y adalah 73,9143 dengan deviasi standar 8.87949.
Adapun nilai koefisien korelasi antara variabel x dengan variabel y adalah 0,924, dengan nilai Signya 0,000 dalam arti kesalahan menolak Ho hanyalah 0% atau mendekati 0%. Hasil pada Sig. itu dapat dicek ulang dengan membanding rhitung 0,924 dengan rtabel untuk dk.: 35 (jumlah sampel) dikurangi 2 (jumlah variabel) = 33. Nilai tabel untuk 33 dengan kesalahan 5%: 0,344 dan 1%: 0,442. Karena rhitung lebih besar dari rtabel, maka berarti Ho ditolak dan Ha diterima. Ini mengandung pengertian bahwa kesimpulan dari sampel ini dapat digeneralisasikan untuk populasi. Dan karena rhitung tidak bertanda negatif, maka menunjukkan arah korelasi ini positif. Jadi, semakin tinggi nilai rata-rata Statistik Pendidikan, Metode Penelitian, dan Metode Penelitian kependidikan semakin tinggi pula nilai Skirpsinya.
Bila penghitungan di atas kita menggunakan SPSS, maka product moment ini ada dua cara untuk menghitung dengan Microsoft Excel. Yang satu menggunakan sub menu Data Analysis… dalam menu Tools, yang satunya menggunakan aplikasi sesuai dengan rumus seperti terlihat di bawah ini:
Caranya:
1. Setelah data dimasukkan, baik untuk variabel x maupun variabel y, buatlah rata-rata dari masing-masing variabel itu.
2. Kurangi masing-masing skor responden dengan nilai rata-ratanya.
3. Kuadratkan hasil pengurangan itu.
4. Jumlahkan hasil pengkuadratkan itu.
5. Untuk mengetahui varians untuk sampel bagikan hasil penjumlahan no.4 dengan jumlah sampel dikurangi 1.
6. untuk mengetahui deviasi standar, Carilah akar varians di atas.
7. Kalikan hasil pengurangan dari masing-masing reponden antara variabel x dan y.
8. Jumlahkan skor hasil dari no. 7 di atas.
9. Setelah itu masukkan ke dalam rumus.
rxy =
Ternyata hasilnya sama persis dengan penghitungan dengan SPSS.
Apabila kita menggunakan rumus 2, maka sebagaimana berikut:
Caranya:
1. Setelah data dimasukkan, baik untuk variabel x maupun variabel y, jumlahkan masing-masing variabel itu.
2. Kuadratkan masing-masing skor yang ada di varibel x.
3. Jumlahkan hasil pengkuadratkan itu.
4. Kuadratkan masing-masing skor yang ada di varibel y.
5. Jumlahkan hasil pengkuadratkan itu.
6. Kalikan masing-masing skor antara variabel x dan y.
7. Jumlahkan skor hasil pengkalian di atas.
8. Setelah itu masukkan ke dalam rumus.
rxy =
Sedangkan cara yang paling cepat adalah menggunakan Data Analysis dari menu Tools, sebagaimana ada pada gambar di bawah ini:
Setelah keluar gambar sebagaimana di bawah ini klik Correlation dan klik Ok.
Selah keluar gambar di bawah ini, maka bloklah seluruh skor variabel x dan variabel y. Selanjutnya klik Ok.
Inilah hasil dari penghitungan itu, ternyata hasilnya, manakala di belakang koma dijadikan tiga angka maka skornya sama persis dengan penghitungan SPSS dan excel secara urut.
2. Koefisien Ganda
Korelasi ganda merupakan angka yang menunjukkan arah dan kuatnya hubungan antara dua variabel atau lebih secara bersama-sama dengan variabel yang lain. Rumus itu adalah sebagai berikut:
R =
Contoh: Seorang peneliti ingin mengetahui adakah hubungan antara nilai rata-rata mata kuliah Statistik Pendidikan, Metodologi Penelitian, dan Metodologi Penelitian Kependidikan (x1) dan Nilai Mata Kuliah yang mempunyai kaitan erat dengan isi topik skripsi (x2) dengan nilai skripsi (y).
Data ketiga variabel itu dimasukkan pada data view SPSS terlihat sebagai berikut:
Prosedur untuk menguji hipotesis dengan korelasi ganda adalah sama dengan aplikasi product moment:
Pada data view product moment di atas, klik Analyze Correlate Bivariate, sebagaimana gambar di bawah ini:
Setelah itu akan keluar gambar seperti di bawah ini:
Pengisian:
1. Destinasikan ketiga variabel itu ke dalam kotak Variables,
2. Kalau berkeinginan untuk menampilkan rata-rata dan deviasi standar, kliklah Options, maka akan keluar gambar di bawah ini.
3. Setelah itu kliklah pada kotak yang ada di depan Means and …. Setelah itu klik Continue. Abaikan yang lain dan klik Ok, maka akan menghasilkan Output seperti di bawah ini.
Correlations
Dari output di atas, dapat diketahui bahwa jumlah sampel dari penelitian ini adalah 35. Skor rata-rata variabel x1 adalah 74,1143 dengan deviasi standar 10,05213, Skor rata-rata variabel x2 adalah 73,1429 dengan deviasi standar 5,56852. Sementara untuk skor rata-rata variabel y adalah 73,9143 dengan deviasi standar 8.87949.
Adapun nilai koefisien korelasi antara variabel x1 dengan variabel y adalah 0,924, nilai koefisien korelasi antara variabel x2 dengan variabel y adalah 0,847, dan nilai koefisien korelasi antara variabel x1 dengan variabel x2 adalah 0,913. Nilai Sig untuk ketiga korelasi itu adalah 0,000 dalam arti kesalahan menolak Ho hanyalah 0% atau mendekati 0%. Hasil pada Sig. itu dapat dicek ulang dengan membanding rhitung dengan rtabel untuk dk.: 35 (jumlah sampel) dikurangi 2 (jumlah variabel) = 33. Nilai tabel untuk 33 dengan kesalahan 5%: 0,344 dan 1%: 0,442. Karena rhitung lebih besar dari rtabel, maka berarti Ho ditolak dan Ha diterima. Ini mengandung pengertian bahwa kesimpulan dari sampel ini dapat digeneralisasikan untuk populasi. Dan karena rhitung tidak bertanda negatif, maka menunjukkan arah korelasi ini positif. Jadi, semakin tinggi nilai rata-rata Statistik Pendidikan, Metode Penelitian, dan Metode Penelitian kependidikan semakin tinggi pula nilai Skirpsinya, demikian juga semakin tinggi nilai mata kuliah yang terkait dengan isi topik skripsi semakin tinggi pula nilai Skirpsinya. Sayangnya out put itu tidak memperlihatkan skor korelasi kedua variabel x secara bersama-sama dengan variabel y.
Bila penghitungan di atas kita menggunakan SPSS, maka bila dihitung dengan Microsoft Excel aplikasinya seperti terlihat di bawah ini:
Hasil penghitungan dengan Microsoft Excel menghasil skor yang sama dengan skor koefisien korelasi hasil penghitungan SPSS. Kelebihannya ia juga bisa digunakan mencari skor korelasi kedua variabel x secara bersama-sama dengan variabel y, yaitu 0,924. Kalau kita membandingkan rhitung dengan rtabel untuk dk.: 35 (jumlah sampel) dikurangi 3 (jumlah variabel) = 32. Nilai tabel untuk 32 dengan kesalahan 5%: 0,349 dan 1%: 0,449. Karena rhitung lebih besar dari rtabel, maka berarti Ho ditolak dan Ha diterima. Ini mengandung pengertian bahwa kesimpulan dari sampel ini dapat digeneralisasikan untuk populasi.
3. Koefisien Kontingency
Teknik ini digunakan untuk menghitung hubungan antarvariabel bila datanya berbentuk nominal. Teknik ini mempunyai kaitan erat dengan Chi Kuadrat yang digunakan untuk menguji komparative k-sampel independent. Oleh karena itu rumus yang digunakan mengandung nilai Chi Kuadrat. Rumus itu adalah sebagai berikut:
C =
Nilai Chi Kuadrat dihitung dengan rumus:
2 =
Contoh:
Dilakukan penelitian untuk mengetahui ada tidaknya hubungan antara penggunaan alat (teknologi) hitung dengan benar tidaknya hasil hitung dalam penghitungan analisis statistik. Sampel diambil 45 orang, 15 menggunakan kalkulator, 15 menggunakan komputer dengan program microsoft Excel, dan 15 orang menggunakan SPSS.
Data dari penelitian ini adalah data kategori, maka cara untuk memasukkan data ke SPSS juga harus sesuai dengan aturan data kategori. Bila sub menu value labels dalam menu view diaktifkan maka akan keluar seperti gambar di bawah ini.
Setelah itu klik Analyze Descriptive Statistics Crosstabs seperti di bawah ini:
Setelah itu akan keluar gambar seperti di bawah ini:
Setelah itu destinasikan kedua variabel itu ke kotak Row(s).
Kliklah Statistics akan keluar seperti di bawah ini:
Setelah itu Aktifkan Chi-square dan Contingency Coeficient dalam Nominal, selanjutnya kliklah Continue.
Setelah itu klik cells maka akan keluar gambar di bawah ini:
Setelah itu aktifkan expected lalu klik Continue. Abaikan yang lain dan kliklah Ok, maka akan keluar Output seperti di bawah ini:
Crosstabs
Dari Output di atas dapat diketahui bahwa nilai hitung koefisien kontingensi adalah 0,514 sementara nilai Chi kuadratnya adalah 16,123. Sementara penghitungan dengan Excel sebagaimana contoh di bawah ini. Dari kedua penghitungan ini ternyata menghasilkan nilai yang sama baik untuk nilai Chi kuadrat maupun Korelasi Koefisien Kontigency.
Cara Mencari Expexted adalah dengan mengkalikan prosentase jumlah yang benar dan yang salah dengan jumlah masing-masing sampel:
Benar : 0.755556 x 15 = 11.3333
Salah : 0.244444 x 15 = 3.6666
Untuk menguji Nilai Koefisien Kontingency menggunakan nilai Chi Kuadrat dengan derajat kebebasan: kategori variabel x dikurangi 1 dan kategori variabel y dikurangi 1. Jadi 3 –1 = 2 ditambah 2 – 1= 1 sama dengan 3.
16.123 > 7,815 kesalahan 5%
16.123 > 11,341 kesalahan 1%.
Ho ditolak Ha diterima
Jenis teknologi hitung mempunyai korelasi yang signifikan dengan kebenaran hitung sebesar 0.514. Dan kesimpulan dari data sampel berlaku juga pada populasi.
4. Spearman Rank
Sebagaimana tabel teknik analisis korelasi, maka spearman rank adalah teknik analisis manakala datanya berbentuk ordinal atau interval yang diordinalkan.
Contoh:
Untuk mendapatkan data tentang karakteristik pemimpin yang berpengaruh, pada tahun 1995 dan 2002 telah diadakan penelitian di Afrika, Asia, Eropa, Amerika Utara, Amerika Selatan, dan Australia diperoleh data dengan peringkat sebagai berikut:
Setelah data diinput sebagaimana di atas, maka klik Analyze Correlate Bivariate sebagaimana gambar berikut ini:
Setelah keluar gambar di bawah ini, masukkan dua variabel tersebut (th2002 dan th1995) ke dalam kolak Variables. Klik Pearson untuk menghilangkan contengannya sebagai gantinya kliklah Spearman, lalu klik Ok.
Out put di bawah ini adalah hasil penghitungan SPSS, yaitu korelasi antara hasil penelitian th 1995 dengan th 2002 yang mempunyai skorhitung: 0,959.
Nonparametric Correlations
Bila dibandingklan rhotabel untuk n = 20 dengan taraf kesalahan 5%: 0,450 dan taraf kesalahan 1%: 0,591. Dikarenakan rhohitung (0,959) adalah lebih besar dari rhotabel baik untuk kesalahan 5% maupun 1%, maka korelasi antara penilaian tahun 1995 dan 2002 adalah positif dan signifikan dan berlaku juga untuk populasi.
Sedangkan aplikasi dengan Excel adalah sebagai berikut:
1. masing-masing skor pada variabel x dikurangi dengan masing-masing skor pada variabel y.
2. masing-masing hasil pengurangan itu dikuadratkan.
3. Seluruh hasil pengkuadratan itu dijumlahkan.
4. Hasil penjumlahan itu dimasukkan ke dalam rumus di bawah ini
= 1 -
Hasilnya ternyata sama persis dengan hasil penghitungan dengan SPSS.
5. Kendall’s tau
Fungsi dari Kendall's tau semestinya sama dengan spearman, bedanya hanyalah kalau spearman biasanya digunakan untuk sampel kecil, tetapi kendall's tau dapat digunakan untuk sampel besar.
Kendall's tau juga sering digunakan untuk menganalisis data yang semula direncanakan dianalisis dengan product moment. Setelah diuji distribusi datanya ternyata tidak normal atau sampelnya kurang dari 30, maka akhirnya dianalisis dengan Kendall's tau. Untuk kasus seperti itu, bila dianalisis dengan menggunakan excel, maka data yang semula interval atau rasio harus dirangking.
Sedangkan prosedur untuk analisisnya sama dengan spearman, bedanya kalau yang diaktifkan untuk kendall's tau adalah kendall.
Setelah seluruh prosedur sebagaimana di spearman dilakukan maka akan keluar out put sebagaimana di bawah ini:
Nonparametric Correlations
Berdasarkan out put di atas, maka diketahui bahwa korelasi antara variabel x (IQ) dan y (prestasi) adalah 0,760. Selanjutnya hasil itu dimasukkan dalam rumus z, yang akan penulis jelaskan berbarengan dengan penjelasan aplikasi dengan excel.
Dari perhitungan ini diketahui bahwa terdapat hubungan positif antara IQ dan prestasi sebesar 0,76. Hal ini berarti semakin tinggi IQ seseorang semakin tinggi prestasinya.
Sedangkan aplikasi analisis kendall's dengan excel adalah sebagai berikut:
1. Skor dari variabel x dirangking dari rangking 1 dan seterusnya.
2. Skor dari variabel y juga dirangking.
3. Berdasarkan rangking dari variabel y itu dicari rangking atas (Ra), yaitu menghitung skor yang yang lebih tinggi bila dibandingkan dengan masing-masing skor pada variabel y.
4. Berdasarkan rangking dari variabel y itu dicari rangking bawah (Rb), yaitu menghitung skor yang yang lebih rendah bila dibandingkan dengan masing-masing skor pada variabel y.
5. Selanjutnya masing-masing skor Ra dan Rb dijumlahkan.
6. Hasilnya penjumlahan itu dimasukkan dalam rumus.
=
Hasil penghitungan dengan Excel ini ternyata mempunyai hasil yang sama dengan SPSS. Selanjutnya hitung 0,760 itu dimasukkan ke dalam rumus di bawah ini.
z =
Zhitung: 5,3249, bila dibandingkan dengan ztabel pada kesalahan 1% dibagi dua (0,01/2 = 0,005) atau kesalahan 5% dibagi dua (0,05/2 = 0,025). Demikian juga 100% dibagi dua (0,100/2 = 0,50) setelah dikurangi dengan 0,005 = 0,495 skor tabelnya adalah 2,58 atau dikurangi 0,025 = 0,475 skortabelnya 1,96. Ternyata Zhitung lebih besar dibanding ztabel Oleh karena itu Ho ditolak dan Ha diterima.
E. Koefisien Penentu
Koefisien penentu adalah digunakan untuk menjawab berapa persen variabel x mempengaruhi variabel y. Rumus untuk mencari Koefisien penentu adalah:
(Koefisien Korelasi)2 x 100.
Dari analisis korelasi yang sudah dilakukan diatas didapatkan skor korelasi untuk:
1. Product Moment 0,924. Skor penentunya sebesar 85,378%. Ini artinya pengaruh variabel x terhadap variabel sebesar 85,378%, sedangkan yang 14,622% ditentukan oleh variabel lainnya.
2. Korelasi Ganda juga sebesar 0,924. Skor penentunya sebesar 85,378%. Ini artinya pengaruh kedua variabel x terhadap variabel sebesar 85,378%, sedangkan yang 14,622% ditentukan oleh variabel lainnya.
3. Koefisien Kontingensi 0,514. Skor penentunya sebesar 26,420%. Ini artinya pengaruh variabel x terhadap variabel sebesar 26,420%, sedangkan yang 73,580% ditentukan oleh variabel lainnya.
4. Spearman Rank sebesar 0,959. Skor penentunya sebesar 91,968%. Ini artinya pengaruh variabel x terhadap variabel sebesar 91,968%, sedangkan yang 8,032% ditentukan oleh variabel lainnya.
5. Kendall's tau 0,760. Skor penentunya sebesar 57,760%. Ini artinya pengaruh variabel x terhadap variabel sebesar 57,760%, sedangkan yang 42,240% ditentukan oleh variabel lainnya.
Aplikasi untuk mencari Koefisien Penentu dengan Microsoft Excel seperti terlihat di bawah ini:
BAB III
ANALISIS REGRESI
A. Pendahuluan
Korelasi dan regresi mempunyai hubungan yang sangat erat. Setiap regresi selalu ada korelasinya, tetapi belum tentu korelasi dilanjutkan dengan regresi. Korelasi yang dapat dilanjutkan dengan regresi adalah korelasi antara dua variabel yang secara teori atau konsep mempunyai hubungan kausal (sebab akibat) atau hubungan fungsional.
Regresi digunakan manakala ingin diketahui bagaimana variabel y dapat diprediksikan melalui variabel x. Hasil analisis regresi dapat digunakan untuk mmutuskan apakah naik dan turunnya skor variabel y dapat dilakukan melalui menaikkan dan menurunkan variabel x.
B. Regresi Linear Sederhana dan Regresi Ganda Dua Prediktor
Di luar yang disebutkan dua regresi di atas, setidaknya masih ada regresi non-linear dan regresi ganda dengan tiga atau lebih prediktor. Hanya karena jarangnya digunakan dalam analisis penelitian untuk penulisan skripsi, maka ia tidak dijelaskan di sini.
1. Regresi Linear Sederhana
Regresi linear adalah regresi linear di mana variabel yang terlibat di dalamnya hanya dua.
Contoh: peneliti meneruskan hasil penghitungkan product moment yang telah dijelaskan di atas, untuk diketahui persamaan regresinya.
Pada data view product moment di atas, klik Analyze Regression Linear, sebagaimana gambar di bawah ini:
Pada data view product moment di atas, klik Analyze Regression Linear, sebagaimana gambar di bawah ini:
Di bawah ini adalah hasil analisis regresi.
Skor R 0,924 adalah koefisien korelasinya, sementara 0,853 adalah korelasi penentunya.
Tabel Anova memaparkan uji kelinearan. Bila Fhitung < Ftabel, maka Ho diterima (tidak terjadi hubungan linear antardua variabel, tetapi bila Fhitung > Ftabel, maka Ho ditolak (terjadi hubungan linear antardua variabel). Uji linearitas ini juga bisa menggunakan skor Sig. Bila lebih kecil dari 0,05, maka tolak saja Ho.
Persamaan regresinya adalah:
Y = 13,438 + 0,816X.
Keterangan:
Bila tidak ada hasil pembelajaran metode penelitian, metode penilitian kependidikan, dan statistik pendidikan, maka mahasiswa itu akan mendapatkan nilai skripsi 13,438.
Koefisien regresi 0,816 menyetakan bahwa setiap penambahan (karena tanda +) 1% skor di variebl x akan meningkatkan skor variabel y sebanyak 0,816%.
Sebagai contok kalau ada mahasiswa yang mendapatkan skor variabel x sebanyak 70, maka diprediksikan skor variabel y sebagai berikut:
Y = 13,438 + (0,816 x 70)
Y = 70,558.
Bila dihitung dengan Microsoft Excel adalah sebagai berikut:
Y’ = a + bX
Dimana :
Y’ = Subyek dalam variabel dependen yang diprediksikan
a = Harga Y bila X = 0 (harga konstan)
b = Angka arah atau koefisien regresi, yang menunjukkan angka peningkatan ataupun penurunan variabel dependen yang didasarkan pada variabel independen. Bila b (+) maka naik, dan bila (-) maka terjadi penurunan
X = Subyek pada variabel independen yang mempunyai nilai tertentu
Sementara rumus untuk mencari a dan b adalah sebagai berikut:
a =
b =
2. Regresi Ganda Dua Prediktor
Sementara untuk regresi ganda dua prediktor persamaan regresinya adalah Y = a + b1x1 + b2x2.
Untuk aplikasi dengan SPSS, cara sama dengan aplikasi linear, bedanya ketika mendestinasikan variabel x dengan memasukkan kedua variabel x.
Hasilnya sebagaimana tersebut di bawah ini. Dan cara membacanya juga sama dengan hasil regresi linear.
Sedangkan cara untuk mencari persamaan regresi dengan Microsoft Excel adalah dengan menggunakan rumus : Y = a + b1X1 + b2X2.
Keterangan
Y = adalah skor yang diprediksikan
a = intercept atau Konstanta
X1 dan X2 = variabel bebas I dan II
b1 dan b2 = koefisien regresi
Sedangkan cara untuk menghitung harga a, b1, dan b2 menggunakan persamaan rumus sebagai berikut:
b1 =
b2 =
a =
Keterangan:
∑ x12 = ∑ x12 -
∑ x22 = ∑ x22 -
∑ x1 x2 = ∑ x1 x2 -
∑ x1 y = ∑ x1 y -
∑ x2 y = ∑ x2 y -
∑ y2 = ∑ y2 -
Sedangkan aplikasinya sebagai berikut:
Begitulah cara penyelesaian menurut Buku Analisis Data Penelitian dengan Statistik oleh Iqbal Hasan, halaman 74-78. Sayang hasilnya ternyata tidak sama dengan penghitungan dengan SPSS.
BAB IV
ANALISIS KOMPARASI
A. Pendahuluan
Analisis komparasi berarti menguji parameter populasi yang berbentuk perbandingan melalui ukuran sampel yang juga berbentuk perbandingan. Hal ini juga berarti menguji hipotesis mengenai ada tidaknya perbedaan antarvariabel yang sedang diteliti. Jika ada perbedaan, apakah perbedaan itu signifikan atau hanya terjadi secara kebetulan.
B. Macam-macam Teknik Analisis Komparasi
Terdapat dua model komparasi, yaitu komparasi antara dua sampel dan komparasi antara lebih dari dua sampel. Masing-masing juga dibagi menjadi dua jenis, yaitu komparasi antar sampel yang berkorelasi dan komparasi antara sampel yang tidak berkorelasi. Untuk lebih jelasnya dapat dilihat pada gambar berikut ini:
MACAM DATA BENTUK HIPOTESIS
Komparatif (Dua Sampel) Komparatif (Lebih dari dua sampel)
Related Independen Related Independen
NOMINAL Mc Nemar Fisher Exact Probability
X2 Two Sample X2 for k Sample
Cochran Q X2 for k Sample
ORDINAL Sign Test
Wilcoxon Matched Pairs Median Test
Mann-Whitney U Test
Kolmogorov-Smirnov
Wald-Woldfowitz Friedman Two-way Anova Median Extention
Kruskal-Wallis One Way Anova
INTERVAL RASIO T-test of Related T-test of independent
One-way Anova
Two-way Anova
One-way Anova
Two-way Anova
Makalah ini hanya akan menjelaskan sekilas tentang T-test of related dan T-test of independent yang sering digunakan mahasiswa untuk menganalisis data dan menguji hipotesis ketika menulis skripsi.
1. T-test of Related
Statistik parametrik yang digunakan untuk menguji hipotesis komparatif rata-rata dua sampel bila datanya berbentuk interval atau rasio adalah t-test.
Rumus untuk t-test of related adalah:
Contoh:
Dilakukan penelitian untuk mengetahui ada tidaknya perpebaan produktivitas kerja pegawai sebelum dan setelah mendapatkan kendaraan dinas. Berdasarkan 25 sampel pegawai yang dipilih secara random diketahui produktivitas kerja pegawai sebelum dan sesudah mendapatkan kendaraan dinas adalah sebagai berikut:
Setelah data disajikan seperti di atas, lalu klik Analyze Compare Means Paired Samples T Test sebagaimana gambar di bawah ini:
Setelah keluar gambar sebagai berikut: arahkan variabel x (sebelum) dan y (sesudah) ke dalam Paired Variables, lalu klik Ok.
Tampilan di bawah ini adalah hasil penghitungan itu.
T-Test
Out put ini menunjukkan bahwa sampel penelitian ini adalah 25, rata-rata skor produktifitas kerja sebelum mendapatkan kendaraan dinas adalah 74 dan sesudanya adalah 79,2.
Out put ini menunjukkan bahwa korelasi antara variabel sebelum dan sesudah adalah 0,863.
Hal yang sangat penting dari out put di atas adalah thitung: -4,906.
Sedangkan penghitungan dengan excel sebagai berikut:
1. Carilah selisih masing-masing skor sebelum dan sesudah mendapatkan perlakuan.
2. Jumlah seluruh skor dari selisih di atas.
3. Bagi hasil penjumlahan nomor 2 dengan jumlah sampel (dalam hal ini 25)
4. Kurangilan masing-masing hasil nomor 1 dengan hasil bagi nomor 4.
5. Kuadratkan masing-masing hasil pengurangan di nomor 4.
6. Jumlah seluruh skor dari hasil di nomor 5.
7. Hasil dari nomor 6 masukkan ke rumus
Hasilnya ternyata sama dengan penghitungan dengan SPSS.
Dengan derajat kebebasan 25+25-2 = 48, yang tertera dalam tabel yang mendekati 48 adalah 40 untuk kesalahan 5% = 2,021 dan 1% = 2,704. Karena thitung lebih besar dari ttabel. Jadi Ho ditolah dan Ha diterima, artinya berlaku untuk populasi, baik dalam kesalahan 1% maupun 5%
2. T-test of Independent
Terdapat 2 rumus t-test yang dapat digunakan untuk menguji hipotesis komparatif dua sampel independent.
t =
Rumus 1
t =
Rumus 2
1. Bila jumlah anggota sampel 1 dan 2 sama dan varians homogens, maka dapat digunakan rumus 1 dan 2. Untuk mengetahui t tabel digunakan dk yang besarnya= n1 + n2 – 2.
2. Bila jumlah anggota sampel 1 dan 2 tidak sama dan varians homogen, maka dapat menggunakan rumus 2. Besarnya dk adalah n1 - n2 – 2.
3. Bila jumlah anggota sampel 1 dan 2 sama dan varians tidak homogens, maka dapat digunakan rumus 1 dan 2. Untuk mengetahui t tabel digunakan dk yang besarnya= n1 – 1 atau n2 – 1.
4. Bila jumlah anggota sampel 1 dan 2 tidak sama dan varians tidak homogens, maka dapat digunakan rumus 1. Untuk mengetahui t tabel digunakan dk yang besarnya= n1 – 1 dan n2 – 1, dibagi dua dan kemudian ditambah dengan harga t yang terkecil. Sebagai contoh n1 = 25, berarti dk = 24, maka harga t tabel = 2,797. n2 = 13, dk = 12, harga t tabel = 3,005 (untuk kesalahan 1%, uji dua fihak. Jadi harga t tabel yang digunakan adalah (3,005 – 2,797) : 2 = 0,104. Selanjutnya harga ini ditambah dengan t yang terkecil. Jadi 0,104 + 2,797 = 2,901.
Untuk menguji homogenitas varians adalah dengan menggunakan rumus:
F = Varians Terbesar
Varians terkecil
Bila F hitung lebih kecil atau sama dengan F tabel, maka varians homogens.
Contoh:
Dilakukan penelitian untuk mengetahui kecepatan memasuki dunia kerja antara lulusan SMA dan STM di satu sisi, dan antara lulusan PTS dan PTN.
Untuk hasil penelitian perbandingan antara lulusan SMA dan STM datanya adalah sebagai berikut:
Setelah data disajikan seperti di atas, lalu klik Analyze Compare Means Independent Samples T Test sebagaimana gambar di bawah ini:
Setelah keluar gambar seperti di bawah ini destinasikan variabel masa nunggu di Test variable(s) dan lulusan pada Grouping variable. Setelah itu klik Define Groups.
Setelah keluar gambar seperti di bawah ini ketiklah 1 di group 1, dan 2 di kolom Group 2. lalu klik Continue, lalu klik Ok.
Tampilan di bawah ini adalah out-put hasil penghitungan t-test independent dengan SPSS.
T-Test
Tampilan di atas menunjukkan bahwa sampel untuk lulus SMA sejumlah 22 dan lulusan STM 18 orang. Rata-rata lulusan SMA memasuki dunia kerja setelah menunggu selama 2,9091 tahun sementara lulusan STM menunggu 1,7778 tahun.
Hasil penting dari out put di atas adalah untuk thitung manakala variannya homogin adalah 2,858 tetapi manakala hiterogin thitungnya adalah 3,026.
Manakala dihitung dengan excel adalah sebagai berikut:
1. Carilah mean dari sampel SMA maupun STM.
2. Kurangi masing-masing sekor dengan mean masing-masing
3. Kuadratkan masing-masing skor hasil pengurangan nomor 2.
4. Jumlah seluruh skor hasil pengkuadratan pada sampel masing-masing
5. Bagi hasil nomor 4 dengan jumlah sampel dikurangi 1 (Inilah variansnya).
6. Casilah homogenitas varians dengan cara varians terbesar dibagi dengan varians terkecil.
7. Bandingkan hasilnya itu dengan Ftabel, manakala Hhitung lebih kecil atau sama dengan Ftabel, maka berarti varians homogin.
Ternyata hasilnya lebih besar dari tabel, sehingga variannys hiterogin. Karena jumlah sampel tidak sama dan variansnya hiterogin, maka berlaku ketentuan nomor 4 (pada halaman 62).
Dari penghitungan di atas ternyata hasilnya sama dengan SPSS. Karena thitung lebih besar dari ttabel, maka Ho ditolak dan Ha diterima.
Sementara untuk penelitian kedua hasilnya adalah sebagai berikut:
Adapun caranya sama dengan yang tertera pada halaman 63-64. Tampilan di bawah ini adalah out-put hasil penghitungan t-test independent dengan SPSS.
T-Test
Jumlah sampel lulusan PTN dan PTS adalah sama 22.
Sementara hasilnya adalah thitung: 0,115.
Sama seperti di atas, hanya karena varians ini homogin dan jumlah sampel sama, maka berlaku ketentuan nomor 1 halaman 62. Hasilnya juga sama dengan penghitungan SPSS.
Untuk menguji hipotesis thitung dibandingkan dengan ttabel. Ttabel untuk derajat kebebasan 22 + 22 - 2 = 42 (yang mendekati adalah 40 untuk kesalahan 5%, dengan uji 2 fihak adalah 2,021, ternyata thitung 0,115 lebih kecil dari pada ttabel 2,021., maka Ho diterima dan Ha ditolak, berarti tidak terdapat perbedaan
statement trading
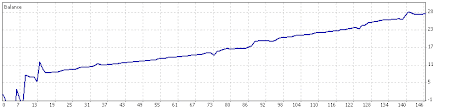
ini adalah hasil live trading EA saya.hasil trading 10% tiap bulan untuk posisi aman, bisa smpe 20-30% untuk posisi spekulasi.jika ada yg berminat contact saya di 085649238006.


trading free $100 no deposit

MARKETIVA

untuk pendaftaran klik gambar diatas dan untuk mendapatkan kupon silahkan kirim email ke saifudinzuhri32@yahoo.co.id
tempat penukaran uang terpercaya

daftar libertyreserve

download gratis dapat uang

payooner
ini adalah perusahaan yang menjual produk ksehatan.dengan daftar disini,kita akan dapat kartu kredit payooner gratis langsung di kirim kerumah kita.silahkan mencoba saya sudah mendapatkan kiriman kartu kreditnya.kegunaan kartu kredit tersebut dapat kita gunakan untuk mengaktifkan rekening paypal. silahkan klik dibawah ini.

Kamis, 25 Juni 2009
Langganan:
Posting Komentar (Atom)
 Forex Quotes
Forex Quotes








Tidak ada komentar:
Posting Komentar
masukkan komentar anda